指针精髓
1. 指针的定义
程序运行时,每一个变量的数据都是保存在内存的一个确定位置,可以用&操作符取得这个内存位置的值。32位操作系统上,这个值实际上就是一个32位的整数。
1 | |
有时候我们需要把这个地址也保存起来,以实现在程序中直接使用。如果每次都对变量取地址,显得不方便。更何况有的情况并没有明确的变量名称,比如动态分配的一块内存。这些内存地址的值都有必要得到保存,因此指针数据类型就闪亮登场了。简单的说:
指针是一个变量,保存的是一个内存地址。
1 | |
这就是定义一个int类型的指针变量pValue来保存iA这个整数的内存地址。
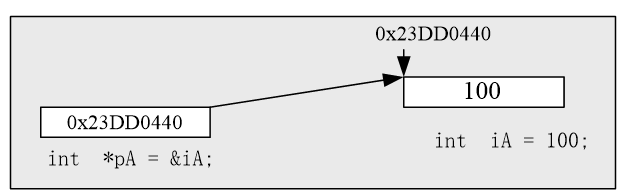
强烈建议指针变量用小写的p表示前缀(p是point的首字母)。
定义指针变量必须注意几点:
1. 指针是对其他的数据类型的复合,指针变量必须指向同类型的变量的地址。比如不能写成:
1
double * pA = &iA; // 错误,iA是整数,和double *不兼容
2. 指针的*位置可以紧靠数据类型,也可以紧靠指针变量,也可以两者都不紧靠。所以下面的三种写法都是可以的:
1
2
3 int *pA = &iA; // 这种写法支持者较多,有的公司编码规范表示推荐这样写
int * pA = &iA; // 这种写法支持者也不少
int* pA = &iA;
3. 指针是一个变量,可以先定义,然后再使用。
1
2
3 int *pA = NULL;
int iA = 200;
pA = &iA;
第1行代码就是对先定义指针变量,并把其初始值定义为NULL。NULL其实就0值,用 NULL更偏向于表示指针初值的意义。指针变量里的值为0,意味着还没有指向任何整数变量的内存地址。
[编程好习惯]
指针变量赋于初值NULL,是编程好习惯的一个体现。有的人甚至支持对所有变量都养成赋予初值的习惯。
2. 指针的基本功能
指针变量的基本功能就是对指针所指向的内存地址的数据进行操作,包括读取数据和修改数据。这里要用到C++的又一个操作符号:取值操作符。值得注意的是和定义指针变量的一样,但取值操作符*不是用在指针变量的声明语句里,而是用在其他语句的指针变量前(紧靠变量)表示取该指针指向的变量的值。这个时候指针变量一定是早已定义好了的变量。
程序实例5-1:Point(指针的基本用法)
1 | |
从程序的运行结果可以看出,指针变量pValue指向iValue后,就可以通过pValue去读数iValue的值。也可以通过对pValue进行赋值达到修该iValue变量的值的效果。这些操作并没有通过iValue进行,而是通过指针变量pValue间接去操作它所指向的变量的数据。所以取值操作符号也叫间访操作符号。间访就是间接访问的意思。
第14行代码通过iValue变量修改了本身的值,因为pValue在程序里一直指向该变量,变量本身值发生变化理所当然会影响后面到pValue取值,所以第16行的*pValue取到的就是变化过的值了。
3. 指针指向数组
数组的名称代表整个数组,其意义等价于一个指针,表示数组的首地址,也就是第一个元素的内存地址。因此,指针可以用来指向数组名称。比如:
1 | |
其意义如下图所表示:

4. 指针指向动态分配内存
一个良好的程序更偏重于运行时的灵活性,编译时对程序过多的限制会削弱程序的质量,有时候甚至降低程序的性能。比如定义一个整数数组来保存学生的成绩,但目前的问题是并不知道学生的数量,如果定义成int arrScore[50]能满足一般的要求,可是在特殊情况学生有200人呢,程序不得不修改成int arrScore[200]。此时对于大多数情况只用了不到50个空间的情况来言,就是对内存空间的浪费。
动态分配内存就是运行时在进程内存空间的自由储存区(也称为堆区)去申请实际可需的内存,然后用来保存数据。
1 | |
4.1 C语言的动态分配内存
C语言用malloc函数来实现内存的动态分配。比如申请100个int的内存空间:
int * pA = (int *)malloc( 100 * sizeof(int) );
这句代码用下图表示其意义:
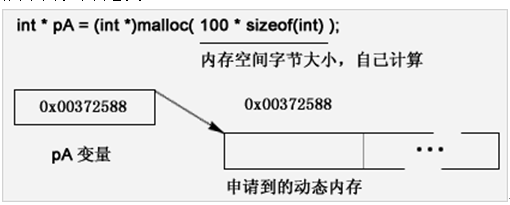
Malloc函数返回一块申请成功的内存,这块内存并没有明确的变量来表示它。我们要使用这块内存,就必须用一定类型的指针去指向它(就是保存他的内存地址,从而知道这块风水宝地在哪里)。这也是C++程序里为什么有指针这种数据类型的原因之一。
使用malloc函数注意三点:
- malloc函数返回的是void *指针,要赋予别的类型指针,必须强制转换。
- 所需要的空间大小需要自己计算。
- 动态分配的内存使用结束后用free函数释放,否则引起内存泄露。
4.2 空类型指针void *的理解
void *表示空类型指针,通常人们又简称为空指针,它仅仅单纯的保存一个内存地址,这个内存地址的数据是什么类型或者这个这个内存地址将要放什么类型的数据取决于后面的实现。Malloc函数返回的就是void *,因为新申请的内存用来装什么类型的数据往往是个未知数,如果你确定了用来装整数,就可以把void *强制转化成int *。如果你心血来潮,想用来装结构变量的数据,还可以转换成结构指针。
程序实例5-1:VoidPoint(空指针的应用理解)
1 | |
程序说明:
第12行先把申请到的内存强制转化成整型指针,说明准备用来装整数。第13行就是利用指针给空间赋一个整数值,然后在第14行输出。
第16行又把申请到的内存用来装一个学生的结构变量,所以先把void*强制转化成结构指针,然后通过第17行直接把一个结构变量赋予到pStudent所指向的内存里。
第18行的(*pStudent)是指针变量取值,因为pStudent是结构指针,所以取值取到的就是一个结构的数据。因为cout并没有能力直接输出一个结构的信息,所以通过点号输出结构里的指定成员的值。
第19行的free是释放动态分配的内存。
此例说明,动态分配的内存可以反复使用,怎么使用取决于程序业务逻辑的实现。
4.3 C++的动态分配内存
C++采用new操作符在堆空间上申请动态内存,使用完后用delete释放。比如:
1 | |
指针也可以指向动态分配的数组空间,比如
1 | |
这里的pA指向一个动态分配的整数数组的首地址(即第1个元素的地址),数组有5个元素。释放这样的内存是:
1 | |
值得注意的是[ ]不能写成(),比如:
1 | |
使用new动态分配内存注意:
- new和delete并不是函数,而是c++的操作符
- new操作符号后必须指定数据类型,如果是数组空间,[ ]里的数字就表示这种数据类型的个数,而不是字节总的大小。
- 由于new操作符指明了数据类型,所以不需要强制转化,就可以用相应数据类型的指针来指向申请成功的动态内存。
5. 指针数组
定义一个整数指针数组:这表明每个元素都是一个整数指针,可以用来保存一个整数变量的内存地址(指向一个整数变量)。如下图所示:1
2int * pA[3];int iA, iB, iC;
pA[0] = &iA; pA[1] = &iB; pA[2] = &iC;
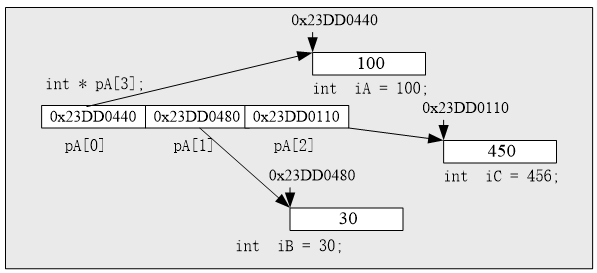
因为指针数组里每个整数指针也可以用来指向一个一维数组,因此指针数组可以用来“模拟”二维数组,只是这里的一维数组在内存上可以不用靠在一起。
1 | |
6. 指针的指针(二级指针)
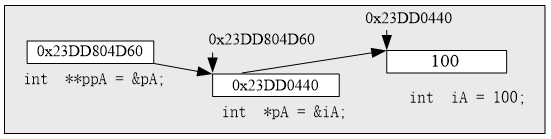
指针的指针简称二级指针,这种指针指向另一个指针变量的内存地址。例如:
1 | |
这里ppA就是一个二级指针,它指向的是另一个指针变量pA的内存地址,而不是一个普通整数变量的内存地址。不能写成:
1 | |
7. 指针的运算
指针的运算通常是指当一个指针指向一个内存地址后,通过一定的偏移指向新的内存地址。比如
1 | |
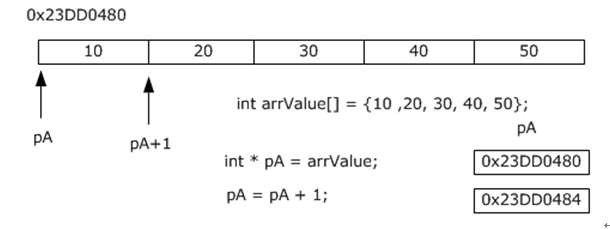
当指针加1后,相当于往后移动了一个数据单位,所移动的内存字节数取决于指针的类型。这里是整数指针,所以内存实际上移动了4个字节。可以得出结论:
指针偏移1个单位,实际移动的字节数等于指针类型所占的字节数。
灵活利用指针的偏移,有时可以使程序代码变得简洁又高效。
8. 指针与字符串
字符串即字符数组,而指针可以指向数组,所以字符指针可以指向字符串。字符指针取值取到的是指针当前指向位置的字符。
程序示例TranslateBig.cpp:把所有字符串转化为大写
1 | |
程序运行结果:
I AM A STUDENT!
程序说明:
(1)、*pszValue字符指针取值取到的是一个字符,由于pszValue++导致指针逐渐往后偏移,所以每次取道的值是不一样的,当取道字符串的最后一个空字符时,由于空字符的ASCII值就是0,0值即为假,所以刚好遍历完字符串后退出循环。
(2)、第10行的函数toupper是把一个函数转化为大写。要使用字符库函数,必须包含头文件<ctype.h>。把取到的字符转化为大写后然后再赋值回去,这里利用了指针来修改数据。
[特别提醒]
很多人定义字符串的时候很喜欢这样定义:
char * pszInfo = “I am a student!”;
这样其意义侧重于定义字符指针,然后指向一个没有名称的常量字符串,这个字符串是不可修改的。对于本例要改变成大写就是不合符要求的。如果你这样定义,可以通过编译,但运行的时候第10行将引起崩溃。
9. 二维数组的指针访问形式
假设定义有二维整数数组:
1 | |
如果要输出第2行第2列的元素值,最简单的形式是利用下标:
1 | |
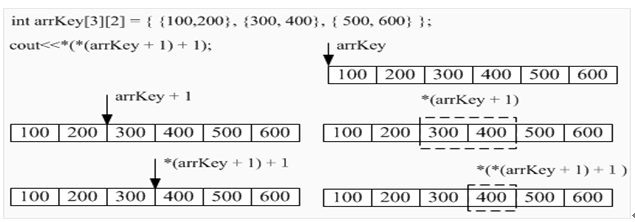
因为arrKey等价于指针,所以也可以通过指针形式来访问第2行第2列的元素值:
1 | |
分析示意图如下图:
10. 数组指针的指针
先看代码:
1 | |
程序运行结果:
1 | |
程序说明:
第14行代码即定义一个指向数组指针的指针。如果写成:
1 | |
编译产生的错误提示:cannot convert from ‘int [3][2]’ to ‘int *’。这说明二维数组名arrValue和一级指针pA是不等价的数据类型,不能相互转化。
二维数组arrValue[3][2]可以看成是一个一维数组arrValue[3],只是这个一维数组里的每个元素又是一个一维数组。二维数组的名称arrValue代表这个一维数组的首地址,而不是一个普通整数元素的地址。所以二维数组名是在一定意义上的二级指针。
注意:
当程序需要指定一个指向数组指针的指针时,别忘了括号。对比一下:
1 | |
指向数组指针的维数一定要一致。
1 | |
编译错误提示:cannot convert from ‘int [3][2]’ to ‘int (*)[5]’
[特别提醒]
指向数组指针的指针是比较难以理解的,所幸的是实际应用极少。原因很简单,既然定义了数组,一般情况下通过数组名称结合下标就可以很方便的访问元素。因此,这种语法如果一时难以理解,并不是一件可怕的事情,你甚至可以不屑一顾,甚至置之不理。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!