unbound源码修改---rbtree用法总结
unbound中大量使用rbtree, 相关用法如下
定义rbtree存储节点数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct ipset_domain_node {
rbnode_type node;
char * domain;
char * name;
};
struct ipset_env {
void* mnl;
int v4_enabled;
int v6_enabled;
const char *name_v4;
const char *name_v6;
rbtree_type * domain_tree;
};定义节点比较函数
1
2
3
4
5
6
7
8//文件间定义
int ipset_domain_cmp(const void* left, const void* right);
// c文件中实现
int ipset_domain_cmp(const void* left, const void* right) {
return strcmp(((struct ipset_domain_node*)left)->domain,
((struct ipset_domain_node*)right)->domain);
}修改
util/fptr_wlist.c中的fptr_whitelist_rbtree_cmp函数
增加新增的比较函数判定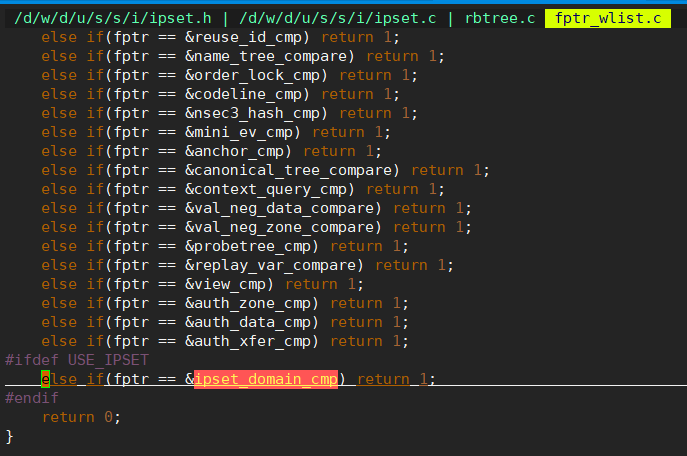
创建rbtree
1
rbtree_type * domain_tree = rbtree_create(&ipset_domain_cmp);插入节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19static void ipset_add_node(rbtree_type * tree, const char * domain,
const char * setname) {
struct ipset_domain_node * node= (struct ipset_domain_node *)calloc(1,
sizeof(struct ipset_domain_node));
if(NULL==domain || NULL==setname) {
return;
}
if(domain[strlen(domain)-1] != '.') {
char tmp[BUFF_LEN] = {0};
snprintf(tmp, BUFF_LEN, "%s.", domain);
node->domain = strdup(tmp);
} else {
node->domain = strdup(domain);
}
node->name = strdup(setname);
node->node.key = node;
rbtree_insert(tree, &node->node);
}
查询节点
1
2
3
4
5
6
7
8
9
10
11if(domain_tree) {
struct ipset_domain_node key, *node;
key.domain = (char*)qname;
key.node.key = &key;
node = (struct ipset_domain_node*)rbtree_search(domain_tree, &key);
if(node) {
setname = node->name;
verbose(VERB_ALGO, "ipset find qname=%s, setname=%s",
qname, node->name);
}
}清理时树节点遍历删除
- 定义树清理时的遍历清理函数
1
2
3
4
5
6
7static void ipset_del_node(rbnode_type* x, void* ATTR_UNUSED(arg)) {
struct ipset_domain_node* v = (struct ipset_domain_node*)x;
verbose(VERB_ALGO, "ipset free domain=%s, name=%s", v->domain, v->name);
free(v->domain);
free(v->name);
free(v);
} - 清理树时调用循环处理函数
1
traverse_postorder(domain_tree, ipset_del_node, NULL);
- 定义树清理时的遍历清理函数
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!